챕터 6의 첫 장을 보게 되면

"배열은 같은 타입의 여러 변수를 하나의 꿈으로 다루는 것"이라고 작성되어 있는데 처음 이걸 보고 어? 이전에 변수를 여러 개 만들고 초기화하는 게 비효율적이라고 생각하면서 왜 여러 개 묶음으로 만들어주는 기능은 없을까 혼자서 고민했던 적이 었었는데 그 방법이 있었다니!!! 너무 좋네요 ㅎㅎㅎㅎ
배열을 생성하기 위해서는 "new"라는 연산자와 함께 배열의 타입과 길이를 지정해 주어야 한다네요

원장님께서 이 부분을 설명하면서 메모리 영역에 대한 설명을 같이 해주셨는데 프로세스(프로그램을 실행시키면 프로세스가 만들어진다고 함)에서는 메모리 영역을 크게 Text, Data, Stack 3가지로 나뉠 수 있고 한 개의 프로세스는 보통 4GB를 가지고 있습니다. 그리고 4GB인 이유는 CPU가 알고 있는 가장 큰 수는 2^32승이고 프로세스 안에? 1바이트가 들어가 있어서 4G x 1Byte 이기 때문에 4GB라고 합니다 ~
메모리 영역에서 Text, Data, Stack처럼 영역이 나뉘는 이유는 각자의 용도를 다르게 사용하기 위함이라고 하네요 집으로 예를 든다면 집도 안방, 화장실, 거실 등으로 나뉘는데 만약 이게 분리가 되어있지 않는다면 잠자는 곳에서 샤워하고 샤워하는 곳에서 음식을 먹는 등 상상을 해보면 굉장히 위화감이 느껴지는 풍경이 떠오르게 되네요.. 핳..
무튼 그런 이유처럼 메모리 또한 영역을 나누게 되었다고 합니다!
Data안에는 Heap이라는 영역이 있고 Heap영역과 Stack영역은 저장공간의 차이라고 하셨다. 예를 들면 커플링은 소중하기 때문에 케이스에 보관을 하고 쓰레기는 쓸모가 없기 때문에 쓰레기통에 버리는 것처럼 Heap과 Stack 또한 마찬가지로 중요하고 오래 보관해야 되면 Heap 영역에 그렇지 않고 불필요하거나 막 쓰는 것은 Stack에 보관을 한다고 합니다.
Heap영역 특징: 중요한 것을 모으는 공간이며, Heap영역에 들어가려면 'new'라는 연산자를 사용해야 하며, 이름을 가질 수 없기 때문에 주소를 갖게 된다.
new라는 연산자는 연산을 수행하면 Heap영역에 해당 크기만큼 할당을 요청하고 할당을 성공하면 할당된 영역의 시작 주소를 돌려준다고 합니다.
그리고 Heap영역에서 이름을 가질 수 없어 주소를 갖는다는 의미는 "int a = 10;"을 보면 "a"라는 이름을 갖고 이 "a"라는 변수에 10이라는 값을 저장할 수 있게 되는데 Heap 영역에 저장되는 int [] a = new int [2]; 는 "a"라는 변수(?)에 int [2]라는 배열의 인덱스 안에 있는 값을 "a"에 저장하는 것이 아닌 int [2]라는 배열의 인덱스 안에 있는 값의 주소를 "a"가 포인팅 해서 가져오는 것이기 때문에 이름이 아닌 주소를 갖는 것이라고 합니다 ~
Heap 영역에는 전역 변수도 포함된다고 하네요!
Stack영역 특징: 막 사용하는 공간(쓰레기통?)이며, 변수가 이름을 가질 수 있습니다.
그리고 지역변수와 매개변수가 이에 해당한다고 합니다 ~
여기까지 메모리 영역이 나뉘는 이유와 Heap, Stack 영역에 대해 말씀을 드렸고 이제 배열의 인덱스와 배열의 길이에 대해 설명해보겠습니다!
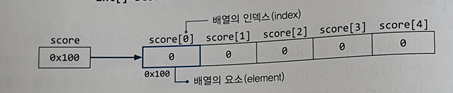
배열의 인덱스는 위의 사진에서 보면 각 저장공간을 "배열의 요소"라고 하며, "배열의 이름[인덱스]"의 형식으로 배열의 요소에 접근합니다. 인덱스는 배열의 요소마다 붙여진 일려 번호라고 생각하시면 돼요! 인덱스를 사용하는 이유는 각 요소를 구별하는 데 사용한다고 합니다 ~ 인덱스는 색인?이라고 해서 책에 수록된 내용들 중 원하는 항목을 쉽게 찾아볼 수 있도록 하게 만드는 것인데 그것과 같은 의미라고 생각하면 될 거 같습니다!
그리고 인덱스의 범위는 "0부터 배열의 길이 -1이다." 여기서 배열의 길이 -1 이게 무슨 의미지? 하시는 분이 계실 수도 있기 때문에 이야기를 드리자면! "int abc = new int [5];"라는 배열을 생성하게 되면 5개의 배열을 생성해줘 라는 의미인데 이것을 직관적으로 보면 1부터 5까지라고 생각하게 되지만 컴퓨터에서는 항상 0부터 시작하기 때문에 0~4이기 때문에
int [5] - 1 이 되는 것이다!!
배열의 길이는 사진으로 대체합니다!

이차원 배열은 1차원 배열의 배열 입니다 ~
타입[][] 변수이름 = new 타입[행의 길이][열의 길이];
// 모두 행의 길이 x 열의 길이 만큼의 값을 저장할 수 있는 공간이 마련된다.- 배열의 생성하면, 배열의 각 요소에는 배열요소타입의 기본값이 자동적으로 저장된다.
- 2차원 배열의 '행index'의 범위는 '0~행의길이-1'이고, '열index'의 범위는 '0~열의길이-1'이다.
- 2차원 배열의 각 요소에 접근하는 방법은 '배열이름[행index][열index]'이다.
- 2차원 배열도 괄호를{}써서 생성과 초기화를 동시에 할 수 있는데, 괄호{}를 한번 더 써서 행별로 구분해 준다.
타입[][] 변수이름 = {
{요소1, 요소2, 요소3},
{요소4, 요소5, 요소6}
};- 2차원 배열은 '배열의 배열'로 구성되어 있다. 1차원 배열들의 참조변수들을 하나의 배열로 또 묶은 것이다. 즉, 여러 개의 1차원 배열을 묶어서 또 하나의 배열로 만든 것이다. 2차원 배열의 각 요소(행)은 1차원 배열이다.
- (1) 배열의 이름인 참조변수 score을 위한 공간 생성 (2) 크기가 5인 일차원 배열 생성. 각 배열 score[0~4]은 실제 값을 담는 배열의 메모리 주소를 저장하는 참조변수이다. (3) 크기가 3인 int형 배열 생성.각 배열의 메모리값 주소는 참조변수 score[0~4]에 저장된다.
그리고 다차원 배열은 2차원 이상의 배열이며, 이차원 배열과 똑같이 선언하고 2차원 배열은 주로 테이블 형태를 데이터를 담는데 사용되며, 3차원 이상의 고차원 배열의 선언은 대괄호[] 개수를 차원의 수만큼 추가해 주면 된다고 합니다!
(다차원 배열은 '배열의 배열'의 형태로 처리한다.)
가변 배열: 전체 배열 차수 중 마지막 차수의 길이를 지정하지 않고, 추후에 각기 다른 길이의 배열을 생성함으로서 고정된 형태가 아닌 보다 유동적인 가변 배열을 구성할 수 있다. (행의 길이는 고정하고, 열의 길이는 각 행마다 다르게 설정할 수 있다).
int[][] score = new int[5][]; // 두 번째 차원의 길이는 지정하지 않는다.
score[0] = new int[4];
score[1] = new int[3];
score[2] = new int[2];
score[3] = new int[2];
score[4] = new int[3];- 1) 참조변수 score을 위한 공간이 만들어진다. 2) 크기가 5인 일차원 배열이 생성된다. 이 배열은 배열의 참조변수를 담는데 사용된다. 참조 변수의 기본 값인 null로 모두 초기화된다. 3) 크기가 4인 int형 배열을 생성한 다음, 그 주소를 참조변수 score[0]에 저장한다. 4) 같은 과정을 score[4]까지 반복한다.
- 이 경우 score.length의 값은 여전히 5로 고정이지만, score[0].length의 값과 score[1].length의 값은 다르다.
- 가변 배열 역시 중괄호{}를 이용해서 생성과 초기화를 동시에 하는 것이 가능하다.
'프로그래밍 > JAVA' 카테고리의 다른 글
| [유튜브 : 뉴렉처님 강의] JDBC 1~ 12강 CRUD (0) | 2022.10.19 |
|---|---|
| 자바 객체지향(2) (0) | 2021.12.29 |
| 자바 객체지향 (1) (0) | 2021.12.28 |
| 자바 조건문과 반복문 (0) | 2021.12.20 |
| Java 변수(variable) (0) | 2021.12.17 |